// Allocate a chunk large enough to hold 'n' bytes, then update // nextfree. Make sure nextfree is kept aligned // to a multiple of PGSIZE. // // LAB 2: Your code here.
if(n == 0){ return nextfree; }
result = nextfree; nextfree = ROUNDUP(nextfree + n, PGSIZE);
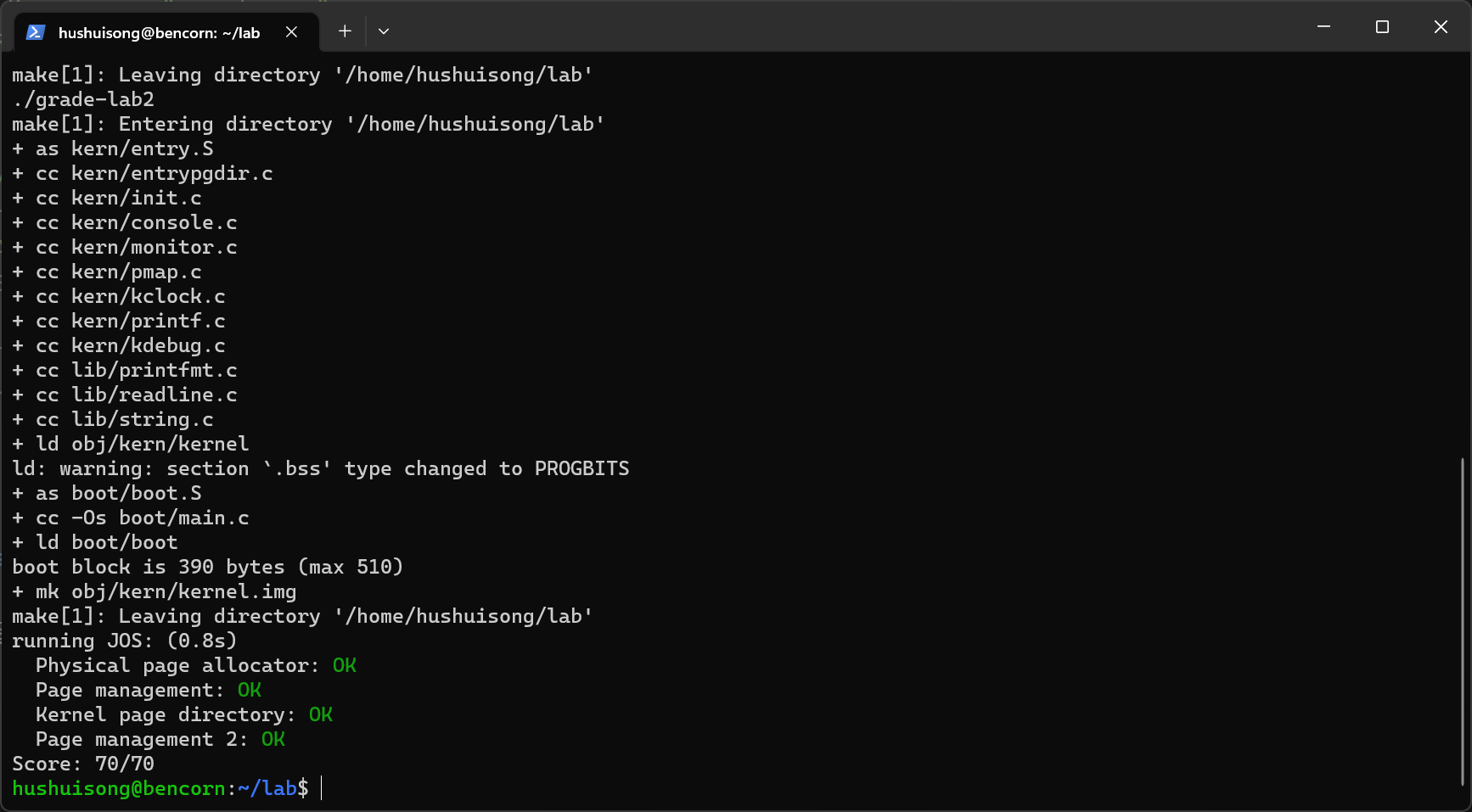
////////////////////////////////////////////////////////////////////// // Allocate an array of npages 'struct PageInfo's and store it in 'pages'. // The kernel uses this array to keep track of physical pages: for // each physical page, there is a corresponding struct PageInfo in this // array. 'npages' is the number of physical pages in memory. Use memset // to initialize all fields of each struct PageInfo to 0. // Your code goes here: pages = (struct PageInfo*)boot_alloc(sizeof(struct PageInfo) * npages); memset(pages, 0 ,sizeof(pages));
void page_init(void) { // The example code here marks all physical pages as free. // However this is not truly the case. What memory is free? // 1) Mark physical page 0 as in use. // This way we preserve the real-mode IDT and BIOS structures // in case we ever need them. (Currently we don't, but...) // 2) The rest of base memory, [PGSIZE, npages_basemem * PGSIZE) // is free. // 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must // never be allocated. // 4) Then extended memory [EXTPHYSMEM, ...). // Some of it is in use, some is free. Where is the kernel // in physical memory? Which pages are already in use for // page tables and other data structures? // // Change the code to reflect this. // NB: DO NOT actually touch the physical memory corresponding to // free pages! size_t i; page_free_list = NULL;
//page 0 in use pages[0].pp_ref = 1; pages[0].pp_link = NULL;
void page_free(struct PageInfo *pp) { // Fill this function in // Hint: You may want to panic if pp->pp_ref is nonzero or // pp->pp_link is not NULL. if(pp->pp_ref){ panic("page->pp_ref is nonzero!\n"); } if(pp->pp_link){ panic("page->pp_link is not NULL!\n"); }
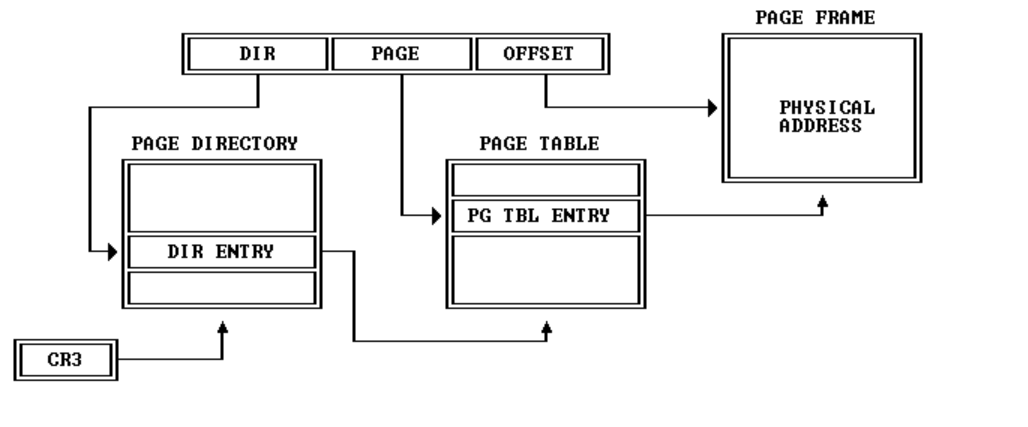
staticvoid boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm) { // Fill this function in size_t i; pte_t *pte; size_t numpage = ROUNDUP(size, PGSIZE) / PGSIZE;
for(i = 0; i < numpage; i ++){ pte = pgdir_walk(pgdir, (void*) va, 1); if(pte == NULL){ panic("boot_map_region: out of memory!\n"); }
////////////////////////////////////////////////////////////////////// // Map 'pages' read-only by the user at linear address UPAGES // Permissions: // - the new image at UPAGES -- kernel R, user R // (ie. perm = PTE_U | PTE_P) // - pages itself -- kernel RW, user NONE // Your code goes here: boot_map_region(kern_pgdir, UPAGES, PTSIZE, PADDR(pages), PTE_U | PTE_P); ////////////////////////////////////////////////////////////////////// // Use the physical memory that 'bootstack' refers to as the kernel // stack. The kernel stack grows down from virtual address KSTACKTOP. // We consider the entire range from [KSTACKTOP-PTSIZE, KSTACKTOP) // to be the kernel stack, but break this into two pieces: // * [KSTACKTOP-KSTKSIZE, KSTACKTOP) -- backed by physical memory // * [KSTACKTOP-PTSIZE, KSTACKTOP-KSTKSIZE) -- not backed; so if // the kernel overflows its stack, it will fault rather than // overwrite memory. Known as a "guard page". // Permissions: kernel RW, user NONE // Your code goes here: boot_map_region(kern_pgdir, KSTACKTOP - KSTKSIZE, KSTKSIZE, PADDR(bootstack), PTE_W);
////////////////////////////////////////////////////////////////////// // Map all of physical memory at KERNBASE. // Ie. the VA range [KERNBASE, 2^32) should map to // the PA range [0, 2^32 - KERNBASE) // We might not have 2^32 - KERNBASE bytes of physical memory, but // we just set up the mapping anyway. // Permissions: kernel RW, user NONE // Your code goes here: boot_map_region(kern_pgdir, KERNBASE, 0xffffffff - KERNBASE, 0, PTE_W);